
标准I/O库提供缓冲的目的:尽可能减少使用read和 write调用的次数。它也对每个I/O流自动地进行缓冲管理,从而避免了应用程序需要考虑这一点所带来的麻烦。
遗憾的是,标准I/O库最令人迷惑的也是它的缓冲。
标准I/O提供了以下3种类型的缓冲
1)全缓冲
在这种情况下,在填满标准I/O缓冲区后才进行实际I/O操作。对于驻留在磁盘上的文件通常是由标准I/O库实施全缓冲的。在一个流上执行第一次I/O操作时,相关标准I/O函数通常调用malloc获得需使用的缓冲区。
术语冲洗(flush)说明标准IO缓冲区的写操作。缓冲区可由标准IO例程自动地冲洗(例如,当填满一个缓冲区时),或者可以调用函数fflush冲洗一个流。
值得注意的是,在UNIX环境中, flush有两种意思:
- 在标准I/O库方面,flush(冲洗)意味着将缓冲区中的内容写到磁盘上(该缓冲区可能只是部分填满的)。
- 在终端驱动程序方面(例如tcflush函数),flush(刷清)表示丢弃已存储在缓冲区中的数据。
2)行缓冲
在这种情况下,当在输入和输出中遇到换行符时,标准I/O库执行I/O操作。这允许我们一次输出一个字符(用标准I/O函数 fputc),但只有在写了一行之后才进行实际I/O操作。当流涉及一个终端时(如标准输入和标准输出),通常使用行缓冲。
对于行缓冲有两个限制:
- 因为标准I/O库用来收集每一行的缓冲区的长度是固定的,所以只要填满了缓冲区,那么即使还没有写一个换行符,也进行I/O操作。
- 任何时候只要通过标准I/O库要求从(a)一个不带缓冲的流,或者(b)一个行缓冲的流(它从内核请求需要数据)得到输入数据,那么就会冲洗所有行缓冲输出流。在(b)中带了一个在括号中的说明其理由是,所需的数据可能已在该缓冲区中,它并不要求一定从内核读数据。很明显,从一个不带缓冲的流中输入(即(a)项)需要从内核获得数据。
3)不缓冲
标准I/O库不对字符进行缓冲存储。例如,若用标准IO函数 fputs写15字符到不带缓冲的流中,我们就期望这15个字符能立即输出,很可能使用 write函数将这些字符写到相关联的打开文件中标准错误流 stderr通常是不带缓冲的,这就使得出错信息可以尽快显示出来,而不管它们是否含有一个换行符。
ISO C要求下列缓冲特征:
- 当且仅当标准输入和标准输出并不指向交互式设备时,它们才是全缓冲的。
- 标准错误决不会是全缓冲的。
但是,这并没有告诉我们如果标准输入和标准输出指向交互式设备时,它们是不带缓冲的还是行缓冲的,以及标准错误是不带缓冲的还是行缓冲的。
很多系统默认使用下列类型的缓冲:
- 标准错误是不带缓冲的。
- 若是指向终端设备的流,则是行缓冲的;否则是全缓冲的。

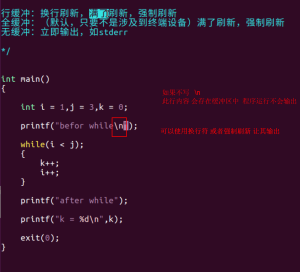
一个进程中 默认打开的三个流:
![]()
标准输入 标准输出 标准出错
强制刷新:fflush(stdout);
强制刷新所有流:fflush(NULL);
© 版权声明
转载请注明出处,并标明原文链接。
本网站尊重知识产权,如有侵权,请及时联系我们删除。
本站所有原创内容仅用于学习和交流目的,未经作者和本站授权不得进行商业使用或盈利行为。
本网站尊重知识产权,如有侵权,请及时联系我们删除。
本站所有原创内容仅用于学习和交流目的,未经作者和本站授权不得进行商业使用或盈利行为。
THE END








暂无评论内容